
Python é uma linguagem extremamente versátil e poderosa, amplamente utilizada em diversas áreas, incluindo a análise estatística. Com bibliotecas robustas como Scipy e StatsModels, você pode realizar desde análises descritivas simples até modelos inferenciais complexos.
Nesta matéria, abordaremos os conceitos básicos de análise estatística com Python, utilizando principalmente as bibliotecas Scipy e StatsModels.
1. O que é Análise Estatística?
A análise estatística é o processo de coletar, explorar e interpretar grandes volumes de dados para descobrir padrões e tendências. Ela se divide em duas categorias principais: estatísticas descritivas e estatísticas inferenciais.
Estatísticas Descritivas: Estas são utilizadas para descrever as características básicas dos dados em um estudo. Elas fornecem resumos simples sobre a amostra e as medidas. A análise descritiva pode incluir medidas como a média, mediana, desvio padrão, e distribuição dos dados.
Estatísticas Inferenciais: Estas são usadas para fazer previsões ou inferences sobre uma população a partir de uma amostra. Envolve a aplicação de testes de hipóteses, intervalos de confiança, e modelos de regressão para fazer suposições informadas baseadas nos dados.
2. Configuração do Ambiente
Para começar, precisamos instalar algumas bibliotecas. Se ainda não as instalou, você pode fazer isso utilizando o pip:
!pip install numpy pandas scipy statsmodels3. Estatísticas Descritivas com Python
Vamos começar importando as bibliotecas necessárias:
import numpy as np
import pandas as pd
from scipy import stats
# Criando um conjunto de dados de exemplo
data = np.random.normal(0, 1, 1000) # 1000 amostras de uma distribuição normalMedidas de Tendência Central
Média: A média é a soma de todos os valores dividida pelo número de valores.
mean = np.mean(data)
print(f'Média: {mean}')Mediana: A mediana é o valor central dos dados quando ordenados.
median = np.median(data)
print(f'Mediana: {median}')Medidas de Dispersão
Desvio Padrão: Mede a dispersão dos dados em relação à média.
std_dev = np.std(data)
print(f'Desvio Padrão: {std_dev}')Variância: É o quadrado do desvio padrão.
variance = np.var(data)
print(f'Variância: {variance}')Quartis: Dividem os dados em quatro partes iguais.
quartiles = np.percentile(data, [25, 50, 75])
print(f'Quartis: {quartiles}')Distribuição dos Dados
Podemos visualizar a distribuição dos dados utilizando histogramas.
import matplotlib.pyplot as plt
plt.hist(data, bins=30, alpha=0.75, edgecolor='black')
plt.title('Histograma da Distribuição dos Dados')
plt.xlabel('Valor')
plt.ylabel('Frequência')
plt.show()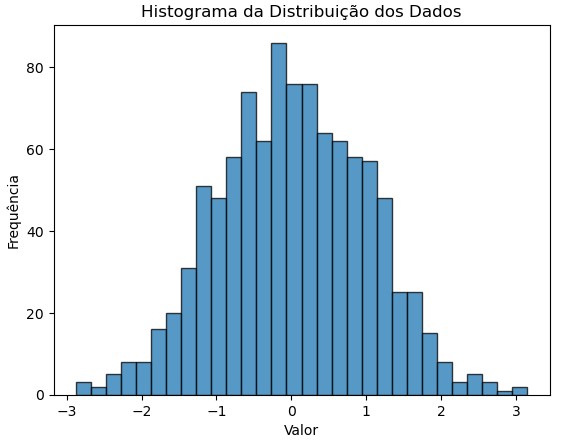
4. Estatísticas Inferenciais com Python
Para análises inferenciais, usaremos a biblioteca StatsModels.
import statsmodels.api as sm
# Exemplo simples de Regressão Linear
# Gerando dados de exemplo
np.random.seed(0)
X = np.random.rand(100, 1)
y = 3 * X.squeeze() + 2 + np.random.randn(100) * 0.5
# Adicionando uma constante (intercepto) aos dados
X = sm.add_constant(X)
# Ajustando o modelo de regressão linear
model = sm.OLS(y, X)
results = model.fit()
# Resumo do modelo
print(results.summary())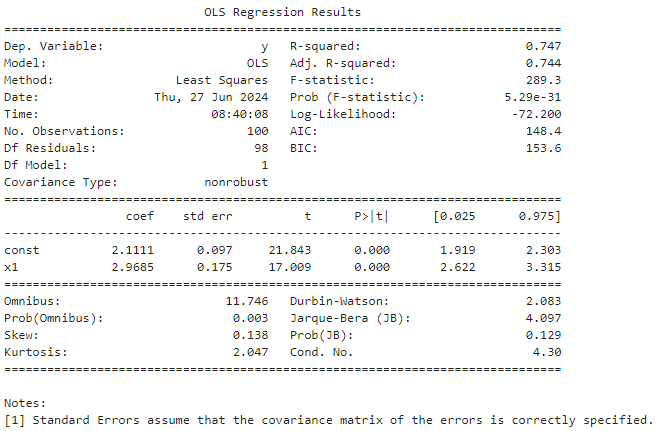
O resumo do modelo fornecerá dados como coeficientes das variáveis independentes, valores p, R-quadrado, e outros diagnósticos importantes para interpretar seu modelo.
5. Testes de Hipóteses
Os testes de hipóteses são uma parte importante das estatísticas inferenciais. Vamos realizar um teste t de uma amostra para verificar se a média da amostra difere significativamente de um valor específico.
# Teste t de uma amostra
t_stat, p_value = stats.ttest_1samp(data, 0) # Testando se a média é significativamente diferente de 0
print(f'Testatística t: {t_stat}, Valor p: {p_value}')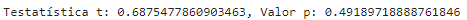
A análise estatística com Python é uma poderosa ferramenta para explorar e entender seus dados. Bibliotecas como Scipy e StatsModels tornam esse processo intuitivo e eficiente. Com as estatísticas descritivas, você pode resumir e visualizar seus dados, enquanto as estatísticas inferenciais permitem testes de hipóteses e criação de modelos preditivos robustos.
Pratique esses conceitos com seus próprios conjuntos de dados para ganhar confiança e proficiência na análise estatística com Python.
Leituras Recomendadas
Se você quer se aprofundar ainda mais na análise estatística com Python, aqui estão algumas leituras recomendadas:
- “Python for Data Analysis” por Wes McKinney: Este livro aborda o uso do Python para análise de dados, incluindo estatísticas descritivas e inferenciais. É uma referência indispensável para qualquer pessoa interessada em análise estatística com Python.
- “Statistics for Business and Economics” por Paul Newbold e William L. Carlson: Este livro explora os conceitos estatísticos fundamentais para negócios e economia. Ele inclui exemplos de Python e aborda métodos estatísticos avançados.
- Documentação oficial do Scipy: A documentação oficial do Scipy fornece exemplos e explicações detalhadas sobre as funcionalidades estatísticas disponíveis nesta biblioteca. É uma fonte valiosa de conhecimento para explorar as capacidades do Scipy.
- Cookbook do StatsModels: O Cookbook do StatsModels é uma coleção de exemplos práticos e soluções de problemas comuns no contexto da modelagem estatística e econometria. Ele fornece orientações úteis para aplicar os recursos do StatsModels em seus projetos.
Ferramentas e Recursos Adicionais
Além das bibliotecas mencionadas, existem outras ferramentas e recursos úteis para análise estatística com Python:
- NumPy: Essa biblioteca é fundamental para a manipulação de arrays e cálculos numéricos em Python. Ela fornece funções eficientes para trabalhar com grandes volumes de dados.
- Pandas: O Pandas é uma poderosa biblioteca para análise de dados que permite manipular, limpar e transformar conjuntos de dados com facilidade. É especialmente útil para gerenciar e explorar conjuntos de dados tabulares.
- Matplotlib e Seaborn: Essas bibliotecas são essenciais para visualização de dados em Python. Elas oferecem uma variedade de gráficos e plotagens para ajudar a entender e comunicar os resultados da análise estatística.
- Jupyter Notebook: O Jupyter Notebook é uma ferramenta interativa para escrever e executar código Python. É perfeito para criar e compartilhar análises estatísticas, permitindo a inclusão de código, resultados e textos explicativos em um único documento.
- Kaggle: O Kaggle é uma plataforma popular para competições de ciência de dados e compartilhamento de conjuntos de dados. Lá, você pode encontrar problemas desafiadores para aprimorar suas habilidades em análise estatística e aprender com a comunidade.
Com essas leituras e ferramentas, você estará bem equipado para realizar análises estatísticas sofisticadas com Python. Explore e experimente diferentes abordagens e técnicas, e aproveite os benefícios de usar uma linguagem de programação flexível e poderosa para suas análises.
Até a próxima! 😉

